

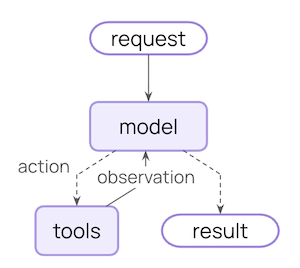
What can middleware do?
Monitor
Track agent behavior with logging, analytics, and debugging
Modify
Transform prompts, tool selection, and output formatting
Control
Add retries, fallbacks, and early termination logic
Enforce
Apply rate limits, guardrails, and PII detection
create_agent:
Built-in middleware
LangChain provides prebuilt middleware for common use cases:Summarization
Automatically summarize conversation history when approaching token limits. The summarization middleware monitors message token counts and automatically summarizes older messages when thresholds are reached. You can configure when summarization triggers and how much context to preserve. Trigger conditions control when summarization runs. You can specify:- A single condition object (all properties must be met - AND logic)
- An array of conditions (any condition must be met - OR logic)
fraction (of model’s context size), tokens (absolute count), or messages (message count). At least one property must be specified per condition.
Keep conditions control how much context to preserve after summarization. Specify exactly one of:
fraction- Fraction of model’s context size to keeptokens- Absolute token count to keepmessages- Number of recent messages to keep
Configuration options
Configuration options
Model for generating summaries. Can be a model identifier string (e.g.,
'openai:gpt-4o-mini') or a BaseChatModel instance. See init_chat_model for more information.Conditions for triggering summarization. Can be:
- A single condition dict (all properties must be met - AND logic)
- A list of condition dicts (any condition must be met - OR logic)
fraction(float): Fraction of model’s context size (0-1)tokens(int): Absolute token countmessages(int): Message count
How much context to preserve after summarization. Specify exactly one of:
fraction(float): Fraction of model’s context size to keep (0-1)tokens(int): Absolute token count to keepmessages(int): Number of recent messages to keep
Custom token counting function. Defaults to character-based counting.
Custom prompt template for summarization. Uses built-in template if not specified. The template should include
{messages} placeholder where conversation history will be inserted.Maximum number of tokens to include when generating the summary. Messages will be trimmed to fit this limit before summarization.
Prefix to add to the summary message. If not provided, a default prefix is used.
Deprecated: Use
trigger: {"tokens": value} instead. Token threshold for triggering summarization.Deprecated: Use
keep: {"messages": value} instead. Recent messages to preserve.Human-in-the-loop
Pause agent execution for human approval, editing, or rejection of tool calls before they execute.Configuration options
Configuration options
Mapping of tool names to approval configs. Values can be
True (interrupt with default config), False (auto-approve), or an InterruptOnConfig object.Prefix for action request descriptions
InterruptOnConfig options:List of allowed decisions:
'approve', 'edit', or 'reject'Static string or callable function for custom description
Important: Human-in-the-loop middleware requires a checkpointer to maintain state across interruptions.See the human-in-the-loop documentation for complete examples and integration patterns.
Anthropic prompt caching
Reduce costs by caching repetitive prompt prefixes with Anthropic models.Learn more about Anthropic Prompt Caching strategies and limitations.
Configuration options
Configuration options
Cache type. Only
'ephemeral' is currently supported.Time to live for cached content. Valid values:
'5m' or '1h'Minimum number of messages before caching starts
Behavior when using non-Anthropic models. Options:
'ignore', 'warn', or 'raise'Model call limit
Limit the number of model calls to prevent infinite loops or excessive costs.Configuration options
Configuration options
Maximum model calls across all runs in a thread. Defaults to no limit.
Maximum model calls per single invocation. Defaults to no limit.
Behavior when limit is reached. Options:
'end' (graceful termination) or 'error' (raise exception)Tool call limit
Control agent execution by limiting the number of tool calls, either globally across all tools or for specific tools. To limit tool calls globally across all tools or for specific tools, settool_name. For each limit, specify one or both of:
- Thread limit (
thread_limit) - Max calls across all runs in a conversation. Persists across invocations. Requires a checkpointer. - Run limit (
run_limit) - Max calls per single invocation. Resets each turn.
| Behavior | Effect | Best For |
|---|---|---|
'continue' (default) | Blocks exceeded calls with error messages, agent continues | Most use cases - agent handles limits gracefully |
'error' | Raises exception immediately | Complex workflows where you want to handle the limit error manually |
'end' | Stops with ToolMessage + AI message | Single-tool scenarios (errors if other tools pending) |
Configuration options
Configuration options
Name of specific tool to limit. If not provided, limits apply to all tools globally.
Maximum tool calls across all runs in a thread (conversation). Persists across multiple invocations with the same thread ID. Requires a checkpointer to maintain state.
None means no thread limit.Maximum tool calls per single invocation (one user message → response cycle). Resets with each new user message.
None means no run limit.Note: At least one of thread_limit or run_limit must be specified.Behavior when limit is reached:
'continue'(default) - Block exceeded tool calls with error messages, let other tools and the model continue. The model decides when to end based on the error messages.'error'- Raise aToolCallLimitExceededErrorexception, stopping execution immediately'end'- Stop execution immediately with aToolMessageand AI message for the exceeded tool call. Only works when limiting a single tool; raisesNotImplementedErrorif other tools have pending calls.
Model fallback
Automatically fallback to alternative models when the primary model fails.Configuration options
Configuration options
PII detection
Detect and handle Personally Identifiable Information in conversations.Configuration options
Configuration options
Type of PII to detect. Can be a built-in type (
email, credit_card, ip, mac_address, url) or a custom type name.How to handle detected PII. Options:
'block'- Raise exception when detected'redact'- Replace with[REDACTED_TYPE]'mask'- Partially mask (e.g.,****-****-****-1234)'hash'- Replace with deterministic hash
Custom detector function or regex pattern. If not provided, uses built-in detector for the PII type.
Check user messages before model call
Check AI messages after model call
Check tool result messages after execution
To-do list
Equip agents with task planning and tracking capabilities for complex multi-step tasks. Just as humans are more effective when they write down and track tasks, agents benefit from structured task management to break down complex problems, adapt plans as new information emerges, and provide transparency into their workflow. You may have noticed patterns like this in Claude Code, which writes out a to-do list before tackling complex, multi-part tasks.This middleware automatically provides agents with a
write_todos tool and system prompts to guide effective task planning.Configuration options
Configuration options
LLM tool selector
Use an LLM to intelligently select relevant tools before calling the main model.Configuration options
Configuration options
Model for tool selection. Can be a model identifier string (e.g.,
'openai:gpt-4o-mini') or a BaseChatModel instance. See init_chat_model for more information.Defaults to the agent’s main model.Instructions for the selection model. Uses built-in prompt if not specified.
Maximum number of tools to select. Defaults to no limit.
List of tool names to always include in the selection
Tool retry
Automatically retry failed tool calls with configurable exponential backoff.Configuration options
Configuration options
Maximum number of retry attempts after the initial call (3 total attempts with default)
Optional list of tools or tool names to apply retry logic to. If
None, applies to all tools.Either a tuple of exception types to retry on, or a callable that takes an exception and returns
True if it should be retried.Behavior when all retries are exhausted. Options:
'return_message'- Return aToolMessagewith error details (allows LLM to handle failure)'raise'- Re-raise the exception (stops agent execution)- Custom callable - Function that takes the exception and returns a string for the
ToolMessagecontent
Multiplier for exponential backoff. Each retry waits
initial_delay * (backoff_factor ** retry_number) seconds. Set to 0.0 for constant delay.Initial delay in seconds before first retry
Maximum delay in seconds between retries (caps exponential backoff growth)
Whether to add random jitter (
±25%) to delay to avoid thundering herdLLM tool emulator
Emulate tool execution using an LLM for testing purposes, replacing actual tool calls with AI-generated responses.Configuration options
Configuration options
List of tool names (str) or BaseTool instances to emulate. If
None (default), ALL tools will be emulated. If empty list, no tools will be emulated.Model to use for generating emulated tool responses. Can be a model identifier string (e.g.,
'openai:gpt-4o-mini') or a BaseChatModel instance. See init_chat_model for more information.Context editing
Manage conversation context by trimming, summarizing, or clearing tool uses.Configuration options
Configuration options
List of @[
ContextEdit] strategies to applyToken counting method. Options:
'approximate' or 'model'ClearToolUsesEdit options:Token count that triggers the edit. When the conversation exceeds this token count, older tool outputs will be cleared.
Minimum number of tokens to reclaim when the edit runs. If set to 0, clears as much as needed.
Number of most recent tool results that must be preserved. These will never be cleared.
Whether to clear the originating tool call parameters on the AI message. When
True, tool call arguments are replaced with empty objects.List of tool names to exclude from clearing. These tools will never have their outputs cleared.
Placeholder text inserted for cleared tool outputs. This replaces the original tool message content.
Custom middleware
Build custom middleware by implementing hooks that run at specific points in the agent execution flow. You can create middleware in two ways:- Decorator-based - Quick and simple for single-hook middleware
- Class-based - More powerful for complex middleware with multiple hooks
Decorator-based middleware
For simple middleware that only needs a single hook, decorators provide the quickest way to add functionality:Available decorators
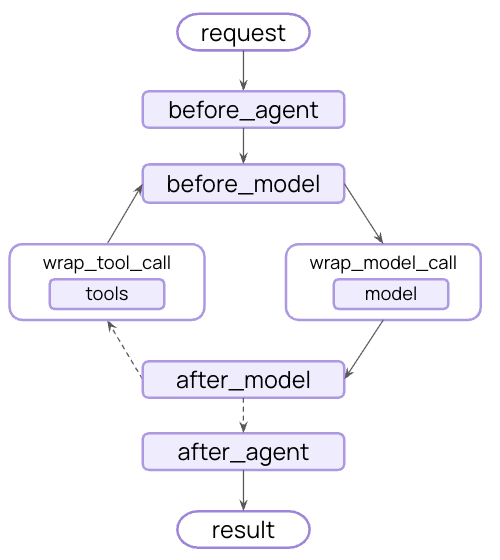
Node-style (run at specific execution points):@before_agent- Before agent starts (once per invocation)@before_model- Before each model call@after_model- After each model response@after_agent- After agent completes (once per invocation)
@wrap_model_call- Around each model call@wrap_tool_call- Around each tool call
@dynamic_prompt- Generates dynamic system prompts (equivalent to@wrap_model_callthat modifies the prompt)
When to use decorators
Use decorators when
• You need a single hook
• No complex configuration
• No complex configuration
Use classes when
• Multiple hooks needed
• Complex configuration
• Reuse across projects (config on init)
• Complex configuration
• Reuse across projects (config on init)
Class-based middleware
Two hook styles
Node-style hooks
Run sequentially at specific execution points. Use for logging, validation, and state updates.
Wrap-style hooks
Intercept execution with full control over handler calls. Use for retries, caching, and transformation.
Node-style hooks
Run at specific points in the execution flow:before_agent- Before agent starts (once per invocation)before_model- Before each model callafter_model- After each model responseafter_agent- After agent completes (up to once per invocation)
Wrap-style hooks
Intercept execution and control when the handler is called:wrap_model_call- Around each model callwrap_tool_call- Around each tool call
Custom state schema
Middleware can extend the agent’s state with custom properties. Define a custom state type and set it as thestate_schema:
Execution order
When using multiple middleware, understanding execution order is important:Execution flow (click to expand)
Execution flow (click to expand)
Before hooks run in order:
middleware1.before_agent()middleware2.before_agent()middleware3.before_agent()
middleware1.before_model()middleware2.before_model()middleware3.before_model()
middleware1.wrap_model_call()→middleware2.wrap_model_call()→middleware3.wrap_model_call()→ model
middleware3.after_model()middleware2.after_model()middleware1.after_model()
middleware3.after_agent()middleware2.after_agent()middleware1.after_agent()
before_*hooks: First to lastafter_*hooks: Last to first (reverse)wrap_*hooks: Nested (first middleware wraps all others)
Agent jumps
To exit early from middleware, return a dictionary withjump_to:
'end': Jump to the end of the agent execution'tools': Jump to the tools node'model': Jump to the model node (or the firstbefore_modelhook)
before_model or after_model, jumping to 'model' will cause all before_model middleware to run again.
To enable jumping, decorate your hook with @hook_config(can_jump_to=[...]):
Best practices
- Keep middleware focused - each should do one thing well
- Handle errors gracefully - don’t let middleware errors crash the agent
- Use appropriate hook types:
- Node-style for sequential logic (logging, validation)
- Wrap-style for control flow (retry, fallback, caching)
- Clearly document any custom state properties
- Unit test middleware independently before integrating
- Consider execution order - place critical middleware first in the list
- Use built-in middleware when possible, don’t reinvent the wheel :)
Examples
Dynamically selecting tools
Select relevant tools at runtime to improve performance and accuracy.Additional resources
- Middleware API reference - Complete guide to custom middleware
- Human-in-the-loop - Add human review for sensitive operations
- Testing agents - Strategies for testing safety mechanisms